Event-basierte Systemarchitektur anhand eines Beispiels erklärt
Bei dem zweitägigen Workshop "Event-basierte Systemarchitektur" hatten wir die Möglichkeit, tief in die Welt der modernen Softwarearchitektur einzutauchen. Unter der Leitung von Golo Roden, dem Gründer, CTO und Managing Partner von thenativeweb, lernten wir, wie wir effiziente und datenschutzfreundliche Lösungen für komplexe Systeme entwickeln können.
Nachfolgend wird die event-basierte Systemarchitektur anhand eines Beispiels einer Bank erklärt. Die Bank speichert nicht nur den aktuellen Kontostand, sondern auch eine Liste von Einzahlungen und Abhebungen als sogenannte Events.
Architektur und Event-basierte Systeme
Man stelle sich eine Bank vor, die unser Guthaben verwaltet. Den eigenen Kontostand kann man beispielsweise in einer App nachlesen. Doch was für eine Zahl wird einem da angezeigt? Nehmen wir an, die Bank hätte für jeden Kunden eine Zahl gespeichert, die bei jedem Einkauf und jeder Gutschrift überschrieben wird. Wenn ein Kunde nun wissen möchte, warum sich sein Kontostand geändert hat, könnte die Bank überhaupt keine Auskunft geben, was über die letzten Wochen geändert und zu dem aktuellen Kontostand geführt hat. Eine sinnvollere Variante wäre also, nicht den aktuellen Kontostand sondern eine Liste von Einzahlungen und Abhebungen zu speichern. Diese Liste enthält sogenannte Events und könnte folgendermassen aussehen:
|
Event |
Datum |
Einzahlung |
|---|---|---|
|
Konto eröffnet |
17.02.2023 |
0.00 |
|
Gutschrift erhalten |
18.02.2023 |
100.00 |
|
Essen gegangen |
21.02.2023 |
-200.00 |
|
Lohn erhalten |
03.03.2023 |
4000.00 |
|
… |
… |
… |
Wenn man nun den Kontostand wissen möchte, braucht man lediglich die letzte Spalte aufzuaddieren. Ausserdem kann man jede Transaktion seit der Eröffnung des Kontos einsehen. Da aber eine solche Datenbank über einen längeren Zeitraum stark anwächst, kann eine Abfrage des Kontostands unter Umständen ziemlich lange dauern. Eine Lösung dieses Problems ist die Command-Query-Responsibility-Segregation (CQRS).
Command-Query-Responsibility-Segregation (CQRS)
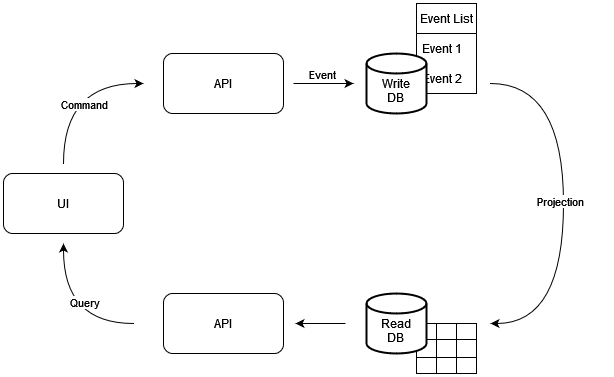
Die Grafik wurde mit Hilfe von draw.io erstellt.
Im Normalfall besteht eine Webapplikation aus einem User Interface (UI), mit dem ein Benutzer über eine Schnittstelle (API) auf eine Datenbank (DB) zugreifen kann. In diesem Fall kann es leicht passieren, dass das Grundprinzip der Command-Query-Separation (CQS) missachtet wird. Diese besagt, dass Abfragen der Datenbank, sogenannte Queries, nur Daten zurückliefern, diese jedoch nicht ändern dürfen. Ein Kommando (Command) hingegen darf nur die Datenbank ändern, jedoch keine Daten zurückgeben. Die Command-Query-Responsibility-Segregation (CQRS) beschreibt eine Softwarearchitektur, welche dieses Konzept verinnerlicht. Dafür implementiert man zwei verschiedene Schnittstellen: Eine, die nur Commands zulässt und eine, die nur Daten zurückgibt, also Queries verarbeitet. Die obere Grafik zeigt dieses Prinzip. Das hat einige Vorteile gegenüber der klassischen Architektur:
- Da Queries viel häufiger vorkommen als Commands, können diese separat behandelt und für eine effiziente Auslese optimiert werden.
- Die beiden verschiedenen APIs ermöglichen es, die Endpoints lesbarer zu beschreiben. Das Query-API besteht nur aus GET-Requests, das Command-API hauptsächlich aus POST-Requests.
Auffällig an der oberen Grafik ist ausserdem, dass nicht nur zwei APIs, sondern auch zwei Datenbanken verwendet werden. Die obere ist eine SQL-Datenbank, die eine Liste von Events beinhaltet. Sie enthält die “echten” Daten und projiziert die für die Darstellung benötigten Werte, wie zum Beispiel den Kontostand, in die untere In-Memory-Datenbank. Das Auslesen von Werten gelingt deutlich schneller bei einer In-Memory-Datenbank als bei einer SQL-Datenbank.
Projektion
Für Datenbankabfragen ist der Event-Store, die Write-DB aus dem obigen Diagramm, nicht sehr geeignet. Wenn wir zum Beispiel wissen möchten, wie viele Konten bereits erstellt wurden, müssten wir alle Konto-Erstellt-Events suchen. Die Lösung dazu ist, eine zweite Datenbank zu erstellen. Im Diagramm oben wäre das die Read-DB. Diese würde dann ein eigenes Feld beinhalten, welches angibt, wie viele Konten bereits erstellt wurden. Der Vorteil von diesem System ist auch, dass diese Datenbank im Arbeitsspeicher gehalten werden kann, wodurch Daten deutlich schneller ausgelesen werden können. Falls der Computer abstürzt, kann die Lesedatenbank aus den Events neu generiert werden.
Dieser Prozess der Synchronisation zwischen den beiden Datenbanken ist die sogenannte Projektion. Dazu schreibt man eine eigene Funktion
void project (event, statistics) {statistics[event.Type] += 1;}
Diese Funktion wird bei jedem neuen Event aufgerufen. C# stellt dafür den sogenannten EventHandler zur Verfügung.
Das Datenschutzproblem
Ein Punkt, der noch nicht erwähnt wurde, ist, dass der Event-Store eine Write-Only-Datenbank ist. Das bedeutet, dass keine Events daraus gelöscht werden. Im Beispiel der Bank macht das durchaus Sinn. Damit der aktuelle Kontostand gerechtfertigt werden kann, müssen die Transaktionen vollumfänglich dokumentiert sein. Dies zieht allerdings ein Datenschutzproblem mit sich: Wenn ein Kunde nun möchte, dass seine Daten gelöscht werden, kann an der Write-Only-Datenbank nichts geändert werden. Für diesen Fall gibt es folgende Lösungsmöglichkeiten:
- Die Daten aus der Lesedatenbank löschen, beziehungsweise nicht mehr projizieren.
- Crypto-Trashing: Es werden nur verschlüsselte Daten gespeichert und jeder Kunde hat seinen eigenen Schlüssel. Anstatt Daten zu löschen, kann man nun einfach den Schlüssel wegwerfen, wodurch nur noch Datenmüll übrig bleibt.
- Keine persönlichen Informationen im Event-Store speichern, sondern nur Pointer, die auf persönliche Informationen in einer weiteren Datenbank zeigen. Dort können sie gelöscht werden. Dadurch zeigen die Pointer dann einfach ins Leere.
Architektur
Eine gute Systemarchitektur weist grundsätzlich eine schwache Kopplung und eine starke Kohäsion auf, wobei die beiden Begriffe wie folgt definiert sind:
- Kopplung beschreibt die Abhängigkeiten zwischen Modulen.
- Kohäsion beschreibt die Abhängigkeiten innerhalb eines Moduls.
Wenn man also Änderungen an einem Modul bzw. einer Klasse vornimmt, möchte man möglichst wenig andere Komponenten ändern müssen. Die Event-basierte Systemarchitektur folgt diesen zwei Prinzipien. Dadurch, dass man Commands und Queries auftrennt, hat man ein System, das eine gute Kohäsion aufweist und eigentlich nur durch die Projektion gekoppelt ist. Möchte man zum Beispiel im UI einen neuen Wert anzeigen lassen, muss man nur Sachen ändern in der Lesedatenbank und in der Projektion. Die Eventdatenbank ist davon nicht betroffen. Ein Nachteil dieser Architektur ist jedoch, dass man einen zeitlichen Abstand hat zwischen dem Schreiben auf den Event-Store und dem Ankommen der Änderung in der Lesedatenbank.
Abschluss
Für weiterführende Informationen empfehlen wir den YouTube-Kanal und die Videosammlung des Referenten Golo Roden.
Kommentare 2
Sehr gut - habe nur einen Tippfehler gesehen: Dazu schreibt man eine* eigene Funktion
Vielen Dank für den Hinweis. Haben wir korrigiert.